In this project we will try to examine the car purchase with our data set which I took from kaggle and we will built a machine learning models with our data set. Data set link
Columns : User ID, Gender, Age, Annual Salary, Purchase Decision (No = 0; Yes = 1)
df.shapeWe have 1000 rows and 5 columns in our data set
df.head()
We are not going to use User ID column so we can drop that column
df = df.drop('User ID', axis ="columns")df["Gender"].value_counts()We have 516 female and 484 male in our data set
df["Purchased"].value_counts()598 customers didn't bought the car and 402 bought
sns.histplot(x = "AnnualSalary", data = df, hue = "Gender")
Seems like female customers earning more salary than male customers in our data set
sns.histplot(x = "Age", data = df, hue = "Gender")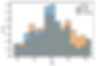
Female customers are older than male customers in our data set
sns.histplot(x = "AnnualSalary", data = df, hue = "Purchased")
As it can expected, customers who has higher income more likely to buy the car
sns.histplot(x = "Age", data = df, hue = "Purchased")
Older customers are more likely to purchase. Now we can get dummy variables for gender column for training our classification models
df = pd.get_dummies(df, drop_first=False)
df = df.drop("Gender_Male",axis ="columns")Now we can get correlation coefficient values on sales and our features
df.corr()["Purchased"].sort_values()
Age is the most correlated feature with our purchasement and annual salary follows it. It seems like gender is not that correlated with purchasement decision. Lets define our X and Y and split them into train and test set
X = df[["AnnualSalary","Age","Gender_Female"]].copy()
y = df[["Purchased"]].copy()from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.30,random_state=100)We will scale our X sets
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_X_train = scaler.fit_transform(X_train)
scaled_X_test = scaler.fit_transform(X_test)We will define a function for comparising our models performances in terms of accuracy score
from sklearn.metrics import accuracy_score
def modelperformance(predictions):
print("Accuracy score in model is {}".format(accuracy_score(y_test,predictions)))Now we can start training classification models with logistic regression.
from sklearn.linear_model import LogisticRegression
log_model = LogisticRegression()
log_model.fit(scaled_X_train,y_train.values.ravel())
log_predictions = log_model.predict(scaled_X_test)
modelperformance(log_predictions)Accuracy score in logistic regression is 0.79. Logistic regression performs well in this classification task. Now lets see how K Nearest Neighbors Classification performs. In order to decide we will use elbow method and grid search both and pick the best one from them. We will start with elbow method.
from sklearn.neighbors import KNeighborsClassifier
test_errors = []
for k in range(1,30):
knn_model = KNeighborsClassifier(n_neighbors=k)
knn_model.fit(scaled_X_train,y_train.values.ravel())
knn_pred = knn_model.predict(scaled_X_test)
test_error_rate = 1 - accuracy_score(y_test,knn_pred)
test_errors.append(test_error_rate)
plt.plot(range(1,30),test_errors)
plt.ylabel("Error Rate")
plt.xlabel("K Neighbors")
It seems like we get the lowest error with K = 10. Lets train our model with K = 10 and check our accuracy score
knn_elbow = KNeighborsClassifier(n_neighbors = 10)
knn_elbow.fit(scaled_X_train,y_train.values.ravel())
knn_pred = knn_model.predict(scaled_X_test)
modelperformance(knn_pred)Our accuracy score with number of neighbors 10 is 0.91. Our KNN model performed well. Lets train support vector machines classification model
from sklearn.svm import SVC
svm = SVC()
param_grid_svr = {'C':[0.01,0.1,0.5,1],'kernel':['linear','rbf','poly']}
gridsvr = GridSearchCV(svm,param_grid_svr)
gridsvr.fit(scaled_X_train,y_train.values.ravel())
pred_svr = gridsvr.predict(scaled_X_test)
modelperformance(pred_svr)Accuracy score is 0.89. Lets train decision tree classification model
from sklearn.tree import DecisionTreeClassifier
treemodel = DecisionTreeClassifier()
treemodel.fit(scaled_X_train,y_train.values.ravel())
treepred = treemodel.predict(scaled_X_test)
modelperformance(treepred)Accuracy score is 0.87. Lets train random forest classification model
from sklearn.ensemble import RandomForestClassifier
rfr_model = RandomForestClassifier()
n_estimators = [32,64,128,256]
max_features = [2,3,4]
bootstrap = [True,False]
oob_score = [True,False]
param_grid_rfr = {'n_estimators':n_estimators,'max_features':max_features,'bootstrap':bootstrap,'oob_score':oob_score}
grid_rfr = GridSearchCV(rfr_model,param_grid_rfr)
grid_rfr.fit(scaled_X_train,y_train.values.ravel())
print(grid_rfr.best_params_)
And train our model with hyperparameters which we found from grid search
rfc = RandomForestClassifier(max_features = 3, n_estimators = 256, oob_score=True)
rfc.fit(scaled_X_train,y_train.values.ravel())
predsrfc = rfc.predict(scaled_X_test)
modelperformance(predsrfc)Accuracy score is 0.87. Best performing classification model was k-nearest neighbors algorithm with K = 10 which we found with elbow method.